本文介绍操作系统对变量的内存管理相关的内容。要能够更清楚的看懂本章的内容,需要先看一下我上一章程序编译原理中提到的操作系统的抽象相关内容。
信息存储
大多数的计算机使用8位的块,或称为字节(byte),来作为最小的可寻址的存储器单位,而不是访问存储器中单独的位。机器级程序将存储器视为一个非常大的字节数组,成为虚拟存储器。存储器的每个字节都由一个唯一的数字来标识,称为它的地址,所有可能地址的集合就称为虚拟地址空间。正如它的名字表明的,这个虚拟地址空间只是展现给机器级程序的概念性映像。实际的实现是随机访问存储器RAM,磁盘存储,特殊硬件和操作系统软件的结合,来为程序提供一个看上去统一的字节数组。
十六进制表示法
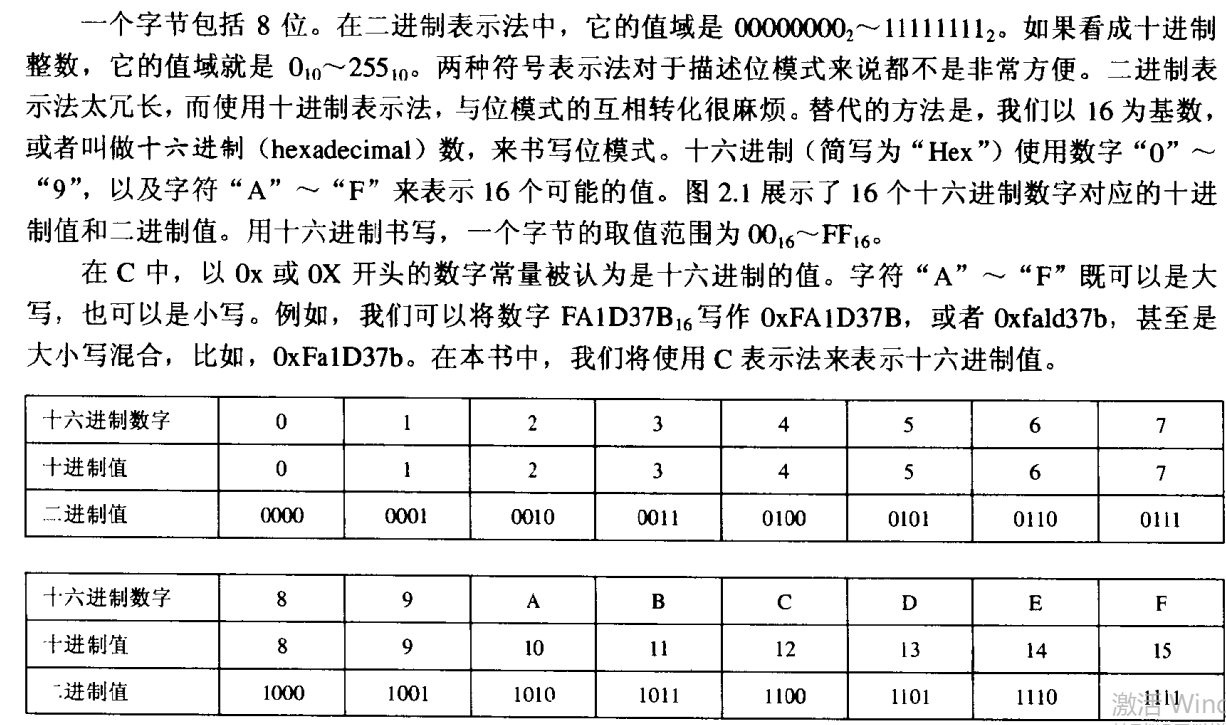
字
每台计算机都有一个字长,指明整数和指针数据的标称大小。因为虚拟地址就是以这样的字来编码的,所以字长决定的最重要的参数是虚拟地址空间的最大大小。也就是说,对于一个字长为n位的机器而言,虚拟地址的范围为0~2^n-1,程序最大访问2^n字节。
今天大多数的计算机的字长为64位,这就限制了虚拟地址空间为8千兆(8GB)。
数据大小
计算机和编译器使用不同的方式来编码数字,比如不同长度的整数和浮点数,从而支持多种数字格式。准确的字节数依赖于机器和编译器。我们展示典型的32位机器和64位机器中的基础类型的字节长度。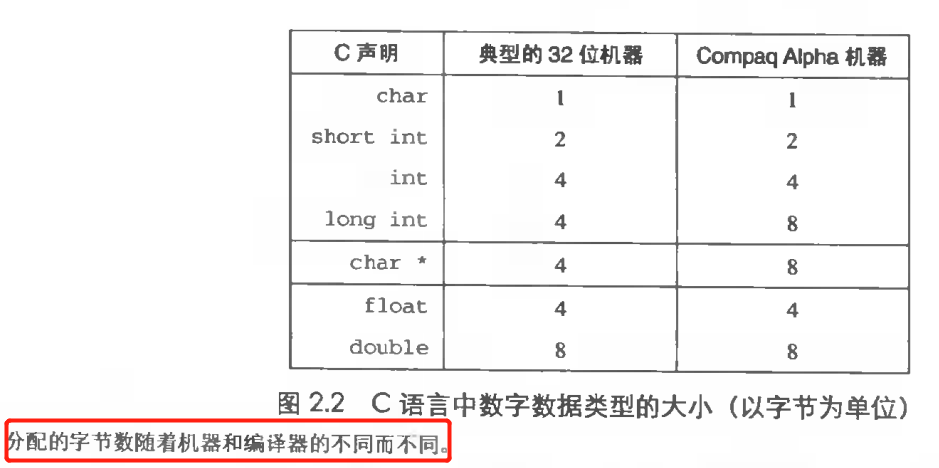
寻址和字节顺序
对于跨越多字节的程序对象,我们必须建立两个规则:
- 这个对象的地址是什么;
- 我们在存储器中如何对这些字节排序;字节排序有两种形式,分为
大端法和小端法:- 小端法:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,最低有效字节在最前面的方式被称为小端法,即数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中;
- 大多数源自以前的Digital Equipment公司(现在是Compaq公司的一部分)的机器及其Intel的机器都采用这种规则。
- 大端法:另外一些机器选择在存储器中按照从最高有效字节到最低有效字节的顺序存储对象,最高有效字节在最前面的方式被称为大端法,即数据的高字节保存在内存的低地址中,数据的低字节保存在内存的高地址中;这个与我们的阅读习惯一致。
- IBM,Motorola,Sun Microsytems的大多数机器都采用这种规则。
- 小端法:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,最低有效字节在最前面的方式被称为小端法,即数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中;
在几乎所有的机器中,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节序列中最小的地址。例如,假设一个类型为int的变量x的地址为0x100,也就是说,地址表达式&x的值为0x100。那么x的四个字节将被存储在存储器的0x100,0x101,0x102,0x103位置。
对于大多数的程序员来说,他们机器字节的顺序是完成不可见的。无论为哪种类型的机器所编译的程序都可以得到相同的结果。不过有时间,字节顺序会成为问题。
不同机器之间通过网络传递二进制数据时,当小端法机器产生的数据被发送到大端法的机器上或者反之时,接受程序会发现字里的字节成了反序的。为了避免这种问题,网络应用程序的代码编写必须遵守已经建立的关于字节顺序的规则,以确保发送方机器将其内部表示转换成网络标准,而接收方机器则将网络标准转换成其内部的表示。
判断机器是大端还是小端的方法;
cint main(int argc, char* argv[]) { union { int a; char c; }Un;//联合体共用内存 //假设当前的内存地址为 00 01 02 03 //int a 4个字节,大端法的内存分布 12 34 56 78; //int a 4个字节,小端法的内存分布 78 56 34 12; Un.a = 0x12345678;//12是数据的高字节哦 if (Un.c == 0x12) std::cout << "big" << std::endl; else if(Un.c == 0x78) std::cout << "little" << std::endl; return 0; }
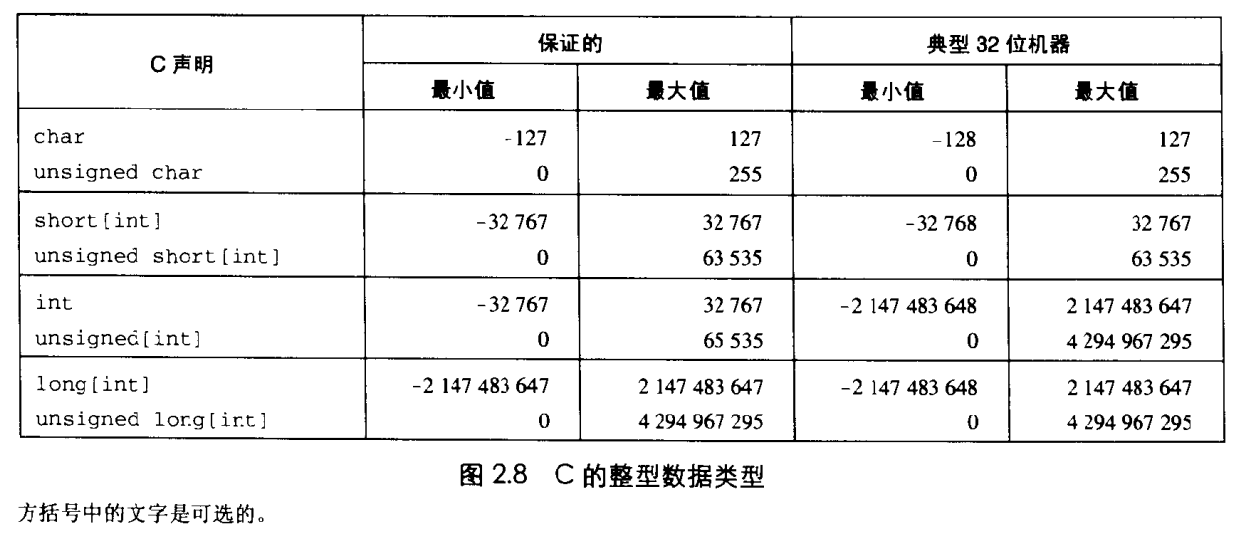
整数数据类型的存储
计算机编码整数有两种方式:
- 一种只能表示非负数;
- 对于这种整数,计算机的存储直接将其转换为对应的二进制,然后直接存储。
- 另一种可以表示负数,零,正数;
- 对于这种整数,计算机通过
二进制补码的方式来进行存储,它的定义是将最高有效位解释为负权,也成为符号位。当被设置为1时,表示值为负数;当被设置为0时,值为非负。 - 原码:就是符号加绝对值
- 反码:正数的反码就是原码,负数的反码是保持符号位不变,其他位取反;
- 补码:正数的补码就是原码,负数的补码为反码+1;
- 对于这种整数,计算机通过
浮点数数据类型的存储
计算机中的浮点数的存储是按照IEEE(电气电子工程师学会)标准来的 
示例可以参考文章
数组分配和访问

指针计算

虚拟存储器
为了更有效的管理存储器并且少出错,现代操作系统提供了一个对主存的抽象概念,叫做虚拟存储器。虚拟存储器是硬件异常,硬件地址翻译,主存,磁盘文件和内核软件的完美交互,它为进程提供了一个大的,一致的,私有地址空间。通过一个很清晰的机制,虚拟存储器提供了三个重要的能力:
- 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效的使用了主存;
- 它为每个进程提供了一致的地址空间,从而简化了存储器管理;
- 它保护了每个进程的地址空间不被其他进程破环。
虚拟存储器是计算机系统最重要的概念之一。它成功的一个主要的原因就是因为它是沉默地,自动的工作,不需要应用程序员的任何干涉。既然虚拟存储器在幕后工作的如此之好,为什么程序员还需要理解它呢?有以下几个原因:
- 虚拟存储器是中心的。虚拟存储器遍及计算机系统的所有层面,在硬件异常,汇编器,链接器,加载器,共享对象,文件和进程的设计中扮演着重要的角色。理解虚拟存储器将帮助你更好的理解系统通常是如何工作的。
- 虚拟存储器是强大的。虚拟存储器给予应用程序强大的能力,可以创建和破坏存储器块,将存储器块映射到磁盘文件的某个部分,以及与其他进程共享存储器。比如,你知道你可以通过读写存储器位置读或者修改一个磁盘文件的内容吗?或者你可以加载一个文件的内容到存储器中,不需要进行任何的显示的拷贝吗?理解虚拟存储器将帮助你利用它的强大的能力在你的应用程序中添加动力。
- 虚拟存储器是危险的。每个应用程序引用一个变量,间接引用一个指针,或者调用一个诸如malloc这样动态分配包程序时,它就会和虚拟存储器进行交互。如果虚拟存储器使用不当,应用将遇到复杂险恶的与存储器有关的错误。例如一个带有错误指针的程序可以立即崩溃于”段错误“或者”保护错误“。
独立的地址空间允许每个进程为它的存储器映像使用相同的基本格式,而不管代码和数据实际存放在物理存储器的何处。例如每个Linux进程使用如图所示的格式。文本区总是从虚拟地址0x08048000处开始的,栈总是从地址0xbfffffff向下伸展,共享代码库总是从地址0x40000000,而操作系统代码和数据总是从地址0xc0000000开始。这样一致性极大的简化了链接器的设计和实现,允许链接器生成全链接的可执行目标文件,这些可执行文件是独立于物理存储器中代码和数据的最终位置。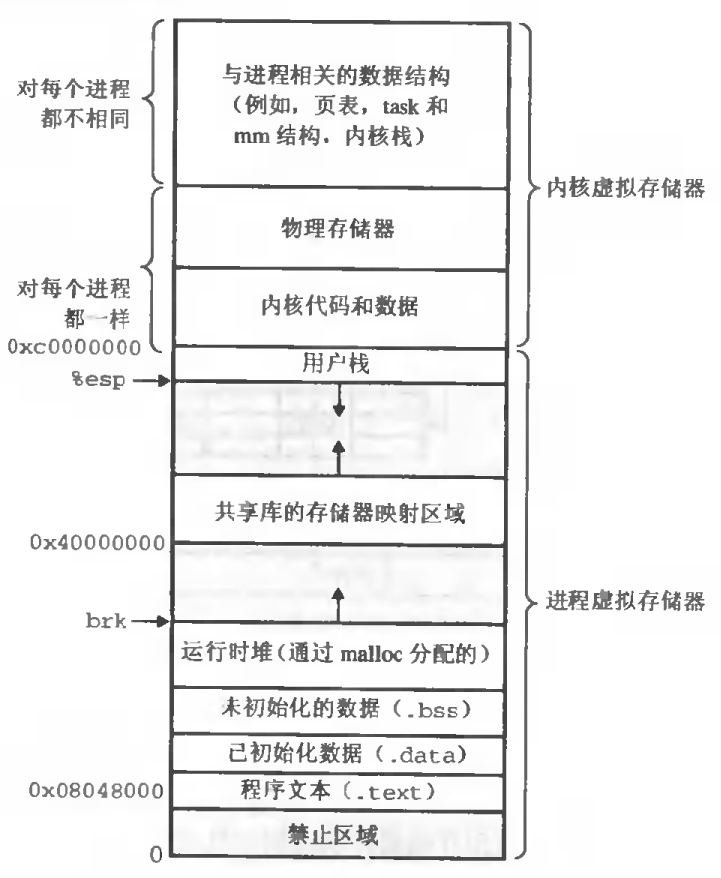
程序中代码和数据的存储位置
在计算机中每个程序的内存是相互独立的,都是在虚拟存储器中开辟的空间。虚拟地址空间(查看我上一篇文章程序编译原理)有大量准确定义的区,每个区都有专门的功能: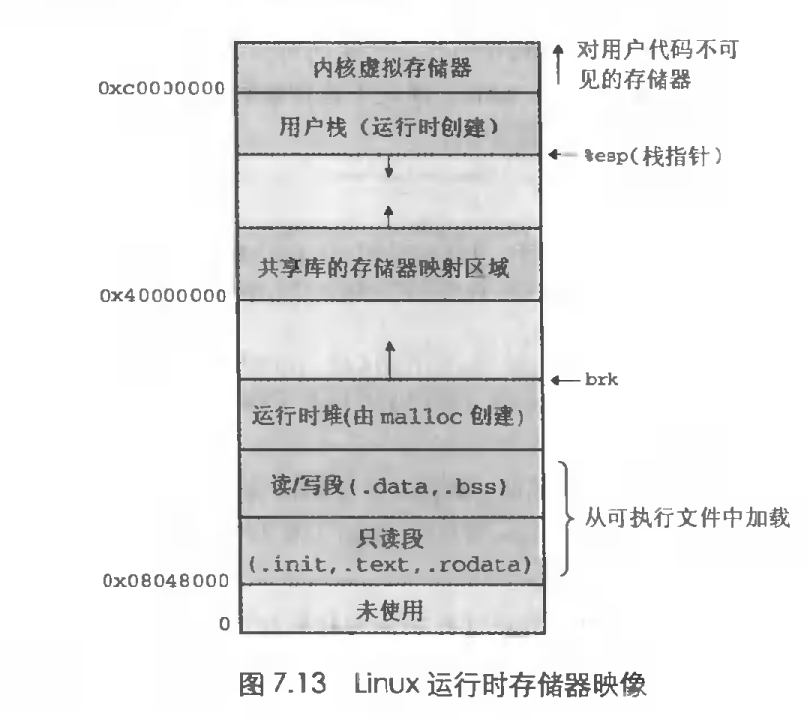
栈:位于虚拟地址空间顶部的是用户栈,系统自己分配,存放临时变量包括,局部变量,返回值,参数,返回地址等;堆: 主要用于动态内存的分配,在程序开发中,一般是开发人员进行分配与释放,读/写区域:主要存放全局变量,静态变量;data:data区里主要存放的是已经初始化的全局变量、静态变量;bss:bss区主要存放的是未初始化的全局变量、静态变量,这些未初始化的数据在程序执行前会自动被系统初始化为0或者NULL;
只读区:主要存放const修饰的变量/字符常量,二进制代码。(关于const变量存疑?)- init:
- text:已经编译的程序的代码;
- rodata:只读数据,比如printf语句中的格式串和switch语句的跳转表;
参考
全文皆是摘录自《深入理解计算机系统》一书,用于自己的学习和理解,若存在侵权请联系作者。
评论